<style>
details {
margin-top: 0.5em;
margin-bottom: 0.5em;
}
summary {
/*font-weight: bolder;*/
}
summary:hover {
text-decoration: underline;
}
blockquote {
font-size: 16px;
}
.todo {
color: #ff00ff;
border: 2px dashed #ff00ff;
padding: 0em 1em;
border-radius: 5px;
margin-top: 1em;
margin-bottom: 1em;
/*display: none; // UNCOMMENT TO HIDE TODOs*/
}
</style>
**[« Back to the main CS 0300 website](https://csci0300.github.io)**
# Project 5B: Distributed Store 🌎 📡
**Deadlines**:
- **Final submission**: **Friday, May 8 at 8:00pm EST**
---
# Introduction
In Project 5A, you implemented a key-value storage system for a single server.
Many major websites like Twitter, AirBnB, and Facebook have so many users that no single server can store all their data, or handle all user requests for data. Instead, they carefully split the data (and the requests accessing it) across many servers. This idea is called *sharding*.
For this assignment, our servers shard by the first character of a key. For example, if our key space is strings comprised of `[A, Z]`, the range `[A, D]` might be one shard, the range `[E, F]` another shard, etc. Then one server would store all keys starting with `A` through `D`, another would store all keys starting with `E` through `F`, etc.
In this assignment, you'll implement:
* A **shardcontroller**, which determines the shards and stores which servers are responsible for each shard,
* A **sharding-aware server** which periodically queries the shardcontroller to determine if any of its shards have been moved to another server, and if so, moves the key-value pairs for that shard to the new server, and
* A **sharding-aware client** which, for each request, queries the shardcontroller to determine which server(s) have the key(s) relevant to its request, then directs its request to those server(s).
:::info
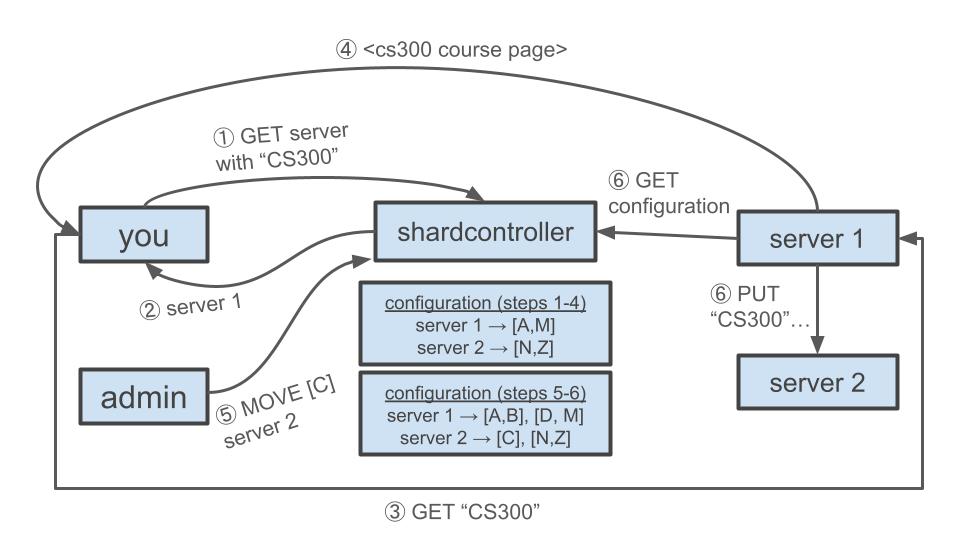
<details><summary>Example Workflow: Courses @ Brown</summary>
Imagine you're searching for courses on C@B. In this scenario, we'll let course codes be the keys and course C@B page content be the values.
1. You enter "CS300" in the search bar. Your computer then:
* Establishes a client connection to the shardcontroller server, and
* Sends a request for the address of the key-value server responsible for the key "CS300."
2. The shardcontroller processes your request and returns that server 1 is responsible for "CS300."
3. Your computer:
* Establishes a client connection to server 1, and
* Sends your request (GET "CS300") to it.
4. Server 1 runs the Get() method you implemented in Project 5A on its key-value store and returns the value (the CS300 course page) to your computer. You made the key-value store thread-safe in Project 5A, so each server can safely process multiple client requests concurrently.
5. Later, a C@B admin:
* Establishes a client connection to the shardcontroller, and
* Issues a "Move" request to assign the shard [C] to server 2.
7. Server 1 queries the shardcontroller periodically. Once it recognizes that the [C] shard has been moved, it:
* Establishes a client connection to server 2, and
* Issues a "Put" request to move the "CS300" key-value pair to server 2. (Note that servers can therefore be clients of other servers!)
Here's a diagram of this workflow:
</details>
<details>
<summary><i><span style="color:#0000EE">Optional: Interested in real-world use cases of sharding?
</span></i></summary>
<br />
> If you're curious how what you're building relates to real-world industry use, take a look at these papers:
> * _[Scaling Memcache at Facebook](https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf)_ by Nishtala et al., which describes how Facebook deploys the memcached key-value store at scale. The store you're implementing in part 1 of this assignment is somewhat similar to memcached.
> * _[Slicer: Auto-Sharding for Datacenter Applications](https://www.usenix.org/system/files/conference/osdi16/osdi16-adya.pdf)_ by Adya et al., which describes Google's auto-sharding system (called "Slicer"). The shardcontroller you will implement in the second part of this assignment is similar to Google's Slicer.
</details>
:::
## Learning Objectives
This assignment will help you:
* **Understand sharding**, a key technique for splitting data in a scalable way across computers.
* **Consider how to manage a distributed system that shards data across servers**, via a centralized controller that has meta-data on which parts of the data each server is responsible for.
* **Understand how the servers in the distributed system manage their responsibilities** by interacting with the centralized controller and reacting to its instructions.
* **Implement a client that talks to the distributed system of servers** in order to read and write sharded data stored on multiple different key-value store servers.
## Assignment Installation
To get started on the project, you will need to pull some additional stencil code into your project repo. You can do this as follows:
1. Open a terminal in your container environment and `cd` into the directory you set up as your project repo from Lab 0 (e.g., `cd projects`)
2. Run the following command to pull the latest code from the `handout` remote (see below if you get errors):
```
cs300-user@9899143429a2:~/projects$ git pull handout main
```
If this reports an error, run:
```bash
git remote add handout git@github.com:csci0300/cs300-s26-projects.git
```
followed by:
```bash
git pull
git pull handout main
```
:::info
:warning: **Important note for this project**: When you run `git pull handout main`, your **git may not pull in any new changes and report `Already up-to-date`**.
**==If there are no changes, that's okay, this is expected==**: we released the stencil code for 5B alongside project 5A: depending on what time you pulled the 5A stencil, you may already have all the code for 5B inside your repo. Therefore, pulling from the repository just helps make sure your repository is up to date.
:::
:::warning
**Note: If you see a warning about "divergent branches"...**
<details> <summary><b>Expand for instructions</b> </summary>

This means you need to set your Git configuration to merge our code by default. To do so, run (within the same directory in your labs repository workspace):
```console
$ git config pull.rebase false
$ git pull handout main
```
</details>
:::
:::danger
**If your terminal window changes to something like this**:

<details> <summary><b>Expand for instructions</b> </summary>
Your terminal has asked you to add a commit message to explain what code was merged in, and opened a text editor so you can write the message. The top line is a default message, which you can use as-is. To use the message and finish the commit, do the following:
- **If your terminal looks like the image above**, press `Ctrl+s` to save, then `Ctrl+q` to quit. (These are shortcuts for the text editor `micro`, which is the program that is running now)
- **If your terminal instead has a bar at the top that says `GNU nano`**, you are using a text editor called `nano`. To save your commit and exit, press `Ctrl+x`, then press `y`, and then press `Enter`.
</details>
:::
Once you have a local working copy of the repository that is up to date with our stencils, you are good to proceed! You should now see a new directory called `kvstore` inside your projects repo: you should do all your work for this project in this directory.
# Part 1: Shardcontroller
First, you'll implement the shardcontroller. The design of this program is inspired by the [Slicer system at Google](https://www.usenix.org/system/files/conference/osdi16/osdi16-adya.pdf), which works the same way.
### Why Are We Doing This?
If we're going to shard our keys across multiple servers (c.f. [Introduction](#Introduction)), then we need to keep track of which server is responsible for which shard. That's what the shardcontroller does!
### Tasks
You'll be working in the `shardcontroller` directory, implementing these methods in `static_shardcontroller.cpp`:
| Name | Arguments | Behavior |
| :--------: | :--------:| :--------: |
| Query |None | Returns the current configuration, i.e., the distribution of shards across key-value servers. |
| Join |The address that the joining server listens on. |The shardcontroller should add the server to the configuration. If the server has already been added, this is considered an error. |
| Leave |The address that the leaving server is listening on. | The shardcontroller should remove the server from the configuration. If at least one server remains in the configuration, the shardcontroller should reassign the leaving server's shards to the server listed first in the configuration.|
| Move |A vector of shard(s) and the address of a key-value server. | Updates the configuration to assign the specified shard(s) to the specified server.|
You may notice the signature for each function is of the pattern `bool XXX(const XXXRequest* req, XXXResponse* res)` for operation `XXX`. When using this pattern, we store the result of the operation (if any) in the `res` pointer. If there was an error doing the operation, we indicate this by returning `false` (instead of `true` if it was successful).
Note that in this part of the project, you are only expected to adapt the configuration data on the shardcontroller. In Part 2, you will actually move keys between key-value servers.
:::info
<details><summary>Example: Configuration Walkthrough</summary>
Three servers running on `elephant:4000`, `tiger:9999` and `bear:713` join. At this point, our shardcontroller configuration should look like this:
| KV Server| Shards |
| -------- | -------- |
| `bear:713` | |
| `elephant:4000` | |
| `tiger:9999` | |
Now, let's say we move `[0, 9]` to `elephant:4000`, move `[A, G]` to `tiger:9999`, and `[H, L]` to `bear:713`:
| KV Server | Shards |
| ----------------- | --------- |
| `bear:713` | `[H, L]` |
| `elephant:4000` | `[0, 9]` |
|`tiger:9999` | `[A, G]` |
Note that we're not required to shard all keys! In this case, no server is responsible for the shard `[M, Z]`.
Say that `bear:713` leaves, so we get:
| KV Server | Shards |
| ----------------- | ---------- |
| `elephant:4000` |`[0, 9]`, `[H, L]` |
| `tiger:9999` | `[A, G]` |
If we move `[2, 5]` to `tiger:9999`, we get:
| KV Server | Shards |
| ----------------- | ---------- |
| `elephant:4000` |`[0, 1]`, `[6, 9]`, `[H, L]` |
| `tiger:9999` |`[2, 5]`, `[A, G]` |
If `bear:713` rejoins and we move `[A, Z]` to it, then we should have:
| KV Server | Shards |
| ----------------- | ---------- |
| `bear:713` | `[A, Z]` |
| `elephant:4000` |`[0, 1]`, `[6, 9]` |
| `tiger:9999` |`[2, 5]` |
Note that the shard `[A, Z]` spanned multiple servers, so both `elephant:4000`'s and `tiger:9999`'s shards were modified.
Also note that you can think of moving as having two steps: first, modifying any shards that are split/removed as a result of the move, and then actually moving the shard(s) to the specified server. For example, in the last move above, the first step modifies `elephant:4000` and `tiger:9999`'s shards to remove `[A, Z]`, and the second step actually adds `[A, Z]` to `bear:713`'s shards.
</details>
:::
::::success
**Task:** Implement the `StaticShardController` methods in the table above in the order that they're listed. More details about these functions can be found in `static_shardcontroller.hpp`. These methods take in Request and Response structs; you can find the struct definitions in `net/shardcontroller_commands.hpp`
<br />
Note that your shardcontroller operations must be thread-safe, since multiple clients could be sending commands to the shardcontroller at the same time. We provide a mutex called `config_mtx` in `static_shardcontroller.hpp` for you to use for this purpose.
<details><summary><strong>Notes/Hints!</strong></summary>
* Notes on `Leave`:
* Our underlying data structure for the configuration is an *ordered* map, so when we say "first remaining server" in `Leave`, you can be guaranteed that when you iterate through the map, the order of key-value pairs is consistent.
* To test that `Leave` correctly reassigns the server's shards, the servers need to have shards in the first place. For servers to have shards, we need to move shards to them. So, we can't fully test `Leave` until after `Move` is implemented--that's what `test_leave_after_move` does.
* `test_handout_example_move` corresponds exactly to the Example: Configuration Walkthrough. If you're having trouble with `Move`, that's a good place to start debugging.
* To see the defintion of `ShardControllerConfig`, see `config.hpp`.
* You do not need to implement (or use) the `ShardControllerConfig::get_server` method in this section--you'll do that in Part 2.
* You may find the C++ std::map [documentation](https://en.cppreference.com/w/cpp/container/map) helpful!
* Before writing `Move`, make sure you read the implementation of the helper function `get_overlap` in `shard.cpp`. You'll find it very useful!
* If you're stuck on a test, you can see how your shardcontroller behaves by running it with a client.
* You *do not* need to merge adjacent shards.
</details>
<br />
**Testing your work**: while working on this task, you should work on passing the passing the `shardcontroller_tests` tests. You can check that your implementation is correct by running **in the `build/` directory**:
```shell
build$ make check B1
```
Here's how you can map the tests onto the functions you'll be implementing:
<details style="padding-bottom:1em"> <summary><b> Expand for details</b> </summary>
- After implementing **Query**, you should not pass any tests (yet).
- After implementing **Join**, you should pass `test_join`.
- After implementing **Leave**, you should pass `test_leave_before_move` and `test_concurrent_joins_and_leaves`.
- After implementing **Move**, you should pass `test_leave_after_move`, `test_handout_example_moves`, `test_complex_moves`, and `test_concurrent_moves`.
</details>
**If you're failing a test**, you should run it individually to see debug output (replace test_name) with the name of the test):
```shell
build$ make test_name # Replace test_name with your test
build$ ./test_name
```
:::warning
**Tip (remember for later)**: For debugging hints and strategies (for this tasks and later tasks), see [**Debugging**](#Debugging), which discusses common errors and how to interpret them!
:::
::::
### Testing it out with a Client
The new client you'll use to test this part is `clients/client`. The client can invoke all the methods specified in the above table on your shardcontroller (run `help` for a list of the available commands). Only move and query will work for now--you'll add support for the other client commands in Part 2!
From the course container, start a couple of servers, one shardcontroller and one client (see [Build & Test](#Build-amp-Test)). From there, you can test out your shardcontroller! Expand the box below for details on how to do this:
:::info
<details><summary>Example</summary>
To test your servers and shardcontroller, you'll need to run each server and the shardcontroller in their own terminals, like this:
**Terminal 1:** Run a shardcontroller on port `13100`
>
```shell
$ ./shardcontroller 13100
Listening on address 29f0c19d87b:13100
```
>
**Terminal 2:** Run a server on port `13101` with 2 workers, and using the address of the shardcontroller (as printed in the previous step--this address will change depending on the name of your container) :
>
```shell
$ ./server 13101 29f0c19d87b:13100 2 # Replace 29f0c19d87b:1310 with the address:port printed when you started with shardcontroller
Listening on address 29f0c19d87b:13101
Shardcontroller on: 29f0c19d87b:13100
join
```
>
**Terminal 3:** Runs a server on port `13102` with 2 workers, then join the shardcontroller configuration:
>
```shell
$ ./server 13102 29f0c19d87b:13100 2 # Replace 29f0c19d87b:13100 with the address of your shardcontroller
Listening on address 29f0c19d87b:13102
Shardcontroller on: 29f0c19d87b:13100
join
```
>
**Terminal 4:** Runs a client:
>
```shell
$ ./client 29f0c19d87b:13100
Connected to shardcontroller at 29f0c19d87b:13100 # Replace 29f0c19d87b:13100 with the address of your shardcontroller
query
29f0c19d87b:13101:
29f0c19d87b:13102:
move 29f0c19d87b:13101 A Z
query
29f0c19d87b:13101: [A, Z]
29f0c19d87b:13102:
move 29f0c19d87b:13102 A Z
query
29f0c19d87b:13101:
29f0c19d87b:13102: [A, Z]
move 29f0c19d87b:13101 0 K Y Z
query
29f0c19d87b:13101: [0, K], [Y, Z]
29f0c19d87b:13102: [L, X]
```
If we then switch back to Terminal 3 and type "leave," the next client query should give:
```shell
query
29f0c19d87b:13101: [0, K], [L, X], [Y, Z]
```
**Note:** The address used this example (`29f0c19d87b`) is computer-specific. You should use the address printed after `Listening on address` when you run `./shardcontroller PORT_NUMBER` on Terminal 1.
</details>
:::
# Part 2: Server
Now that your shardcontroller works, it's time to use it!
### Why Are We Doing This?
So far, the shardcontroller sounds nice, but it doesn't actually move keys between key-value servers. In other words, we haven't touched on how the key-value servers handle configuration changes. If a subset of ids on `server1` gets moved to `server2`, somehow we need to send the key-value pairs stored previously on `server1` to their new home!
### Tasks
Before we handle configuration changes, we'll first make a small optimization to our server. The server code is located in `server/server.cpp`.
Right now, each server needs to manually execute their `Join` and `Leave` requests. It would be nice if instead, the server sends a `Join` request on startup and a `Leave` request on shutdown. (It still *can* issue manual requests if it wants to join/leave without shutting down, but this automation saves some time).
:::success
**Task:** Send a join request to the shardcontroller on startup, and a leave request on shutdown. Once you're done, you should pass `server_tests/test_join_leave`, which you can run via `make check B2`.
**Note:** If you haven't already, be sure to change your key-value store in `start()` to be a `ConcurrentKvStore` instead of a `SimpleKvStore`.
:::
Now that we join and leave the shardcontroller configuration automatically, it's time to respond to configuration changes.
First, you'll implement a helper called `get_server`, which, given the configuration and a key, should return the server responsible for the key. If no server is responsible, it should return `std::nullopt`.
:::success
**Task:** Implement `get_server` in `common/config.cpp`.
Once you're done, you should pass `server_tests/test_get_server`, which you can run via `make check B2`.
**Note:** Take a look at the `Shard` struct in `shard.hpp` for some helpful utilities!
:::
Now, you'll implement a method called `process_config`, which should query the shardcontroller for the current configuration of shards. If the server is no longer responsible for some of its keys, `process_config` should:
* transfer those key-value pairs to the newly responsible server, and
* delete them from its store.
:::info
<details><summary>Important Details About Transferring</summary>
To transfer key-value pairs, your server (the sender) needs to become a client of another server! It's a client because it's the active endpoint of the connection; it will establish a connection to the destination server, send a request to put the key(s), and check that it receives a successful response.
Each server spawns a thread to run `process_config` every 250ms (c.f. `process_config_loop`). This design means that every quarter of a second, your server will update its config, then its key-value store accordingly.
Since each server only updates its config every 250ms, it's possible that one server tries to transfer some key-value pairs to another, but the destination server's config is still out of date. The destination server wouldn't recognize that it's responsible for its new shards, so it rejects the transfer request. That's why it's important to retry transfers until success--if we don't, then the key-value pairs would be lost after the sending server deletes them from its store. If we keep trying, then eventually the destination server will run `process_config`, update its config accordingly, then accept the request. **But note that a retry is not the same as an error!**
</details>
:::
:::success
**Task:** Finish implementing `process_config`. Once you're done, you should pass `server_tests/test_process_config`, which you can run via `make check B2`
<details><summary>Notes</summary>
* We've handled implementing some of `process_config` for you--the remaining tasks are marked TODO.
* Look at `server.hpp`--we've marked the fields you'll need to use.
* How can you use `get_server()` to help you?
</details>
:::
# Part 3: Client
In this section, we'll extend the client from Project 5A to incorporate the shardcontroller.
### Why Are We Doing This?
In Project 5A, you used the `SimpleClient`, which you run like this:
```bash
./simple_client <server address>
```
Then, the simple client sends all of its requests to the specified server.
Now that we're sharding our keys across servers, this design won't work. There's no way for the client to know upon start which server(s) are responsible for the keys in its request. So, we need to extend the client such that it:
* queries the shardmaster for the configuration,
* uses the configuration to determine the server(s) relevant to its request,
* sends its request to those server(s).
### Tasks
Take a look at `shardkv_client.cpp`. We've provided implementations for `Get`, `Put`, `Append`, and `Delete`. Your task is to finish the `ShardKvClient` implementation by writing `MultiGet` and `MultiPut`.
:::success
**Task:** Implement `MultiGet`.
This implementation must be a proper `MultiGet` that invokes the server-side `MultiGet` operation on the KVStore, **not** just a set of repeated calls to `Get` (which would have different atomicity properties). Our tests have a performance component that checks for this.
Once you're done, you should pass `shardkv_client_tests/test_multiget`, which you can run via `make check B3`.
:::
:::success
**Task:** Implement `MultiPut`.
As above, this implementation must be a proper `MultiPut` that invokes the server-side `MultiPut` operation on the KVStore, **not** just a set of repeated calls to `Put` (which would have different atomicity properties). Our tests have a performance component that checks for this.
Once you're done, you should pass `shardkv_client_tests/test_multiput`, which you can run via `make check B3`.
:::
:::info
<details><summary><strong>Hints for MultiPut and MultiGet!</strong></summary>
* Say you have three servers with this configuration:
| KV Server | Shards |
| ----------------- | --------- |
| `bear:713` | `[0, B]` |
| `elephant:4000` | `[C, N]` |
| `tiger:9999` | `[O, Z]` |
and the `ShardKvClient` wants to issue a `MultiGet` request for keys `[apple, banana, clementine. grape, orange, pear]`. It should:
* Determine which servers are responsible for which keys--in this example, `bear:713` has "apple" and "banana", `elephant:4000` has "clementine" and "grape", and `tiger:9999` has "orange" and "pear". You've already written functionality that should help with this!
* Get the values for those keys from the corresponding servers and return them to the client.
* Order matters! If the `ShardKvClient` issues a `MultiGet` request for keys `[malte, nick, christina]`, we would expect to get back `[schwarzkopf, demarinis, paxson]` *in that order*.
* Remember that you can (and should) invoke the `SimpleClient` code when you can--don't accidentally reimplement something we've done for you.
* If you're debugging the tests, try decreasing kNumKeyValuePairs and kNumBatches to make the output more readable.
</details>
:::
### Testing it out with a Client
You should now have a fully functioning `ShardKvClient`! You can test that by:
* Running a shardcontroller in a terminal
* Running a client in a terminal
* Running a couple of servers in (yet more) terminals
* From the client, moving shards to servers
* From the client, issuing `Get`, `Put`, `Append`, `Delete`, `MultiGet`, and `MultiPut` requests and checking that:
* they succeed when they should (i.e., a server is responsible for the keys) and failing otherwise, and
* you get the output you expect.
* From the client, moving shards between servers, printing the store in the servers, and checking that key-value pairs get transferred and deleted properly.
For instructions on how to run these executables, see [Build & Test](#Build-amp-Test) or Part 1's "Testing it out with a client" section.
You now have a fully functioning distributed system! :tada:
# Build & Test
To compile your code:
1. `cd` to the `build` directory (if you are not there already)
2. Compile using `make` or `make -j` (to use parallel builds)
Once you have compiled your project, you can run the shardcontroller, client, and server so that you can interact with them. To do this (see [here](#Testing-it-out-with-a-Client) for an example):
1. First, **start the `shardcontroller`**, by running the following (from the`build` directory):
```shell
$ ./shardcontroller <port> # Example: ./shardcontroller 13100
Listening on address 29f0c19d87b:13100
```
Running the shardcontroller will print a message like `Listening on address <address>:<port>`. The `<address>:<port>` part gives a name you'll use in subsequent commands, so copy it for later.
2. Next, **start a `server`**, by running the following *from a separate terminal* (from the`build` directory):
```shell
$ ./server <port> <shardcontroller_address> <n_workers> # Example: ./server 13101 29f0c19d87b:13100 2
```
where `<shardcontroller_address>` is the `<address>:<port>` printed when you start the shardcontroller. This address will contain a long hex string matching the name of your container, which tells your server how to find the shardcontroller.
Depending on what you want you want to test, you might want to run more than one server. To do this, open more terminals and run the same command again with a different port number (e.g., `./server 13102 29f0c19d87b:13100 2`).
3. Finally, to run the **`client`**, run the following *from a separate terminal* (in the`build` directory), passing in the address of the shardcontroller:
```shell
$ ./client <shardcontroller_address> # Example: ./shardcontroller 29f0c19d87b:13100
```
You can now interact with your shard controller, servers, and clients via REPL commands.
# Testing
We strongly recommend that you test your code often while implementing, by compiling and running a client, server, and shardcontroller (as shown above).
To run the tests, **be sure to `cd` to the `build/` directory**. Then you can run all tests by running `make check 5B`.
You can find the code for all tests in the `tests/` directory, which contains a subdirectory for each part of the assignment. The steps for Project 5B are:
- Step 1: `shardcontroller_tests` (B1)
- Step 2: `server_tests` (B2)
- Step 3: `shardkv_client_tests` (B3)
TO run the tests for an *individual step #* you can run `make check B#`. For example, to run the tests for step 1, you can run `make check B1`.
To run all tests, run `make check 5B` or `make check distributed_store` in the `build` directory.
**If you are failing a test**, you should run the test individually to see more debugging output. To do so, run the executable corresponding to the test name in the `build` directory. For example, to run `test_complex_moves`, do:
```shell
build$ ./test_complex_moves
```
This will let you see the output from the tests, and you can use GDB on the executable as you did in Project 5A. If nothing prints, the test passed. Otherwise, you'll see an error message:
<details><summary>Example</summary>
```
$ ./test_put_get_delete
Assert failed in file test_put_get_delete.cpp on line 26:
Expected first argument to equal second argument x1Ha4M0dLCkK
```
The error message directs us to this assertion:
```cpp=26
ASSERT_EQ(get_res.value, vals[i]);
```
so the error message is telling us that `get_res.value` (the first argument) is empty, but the test expected it to be equal to the second argument, `vals[i]`, or x1Ha4M0dLCkK.
</details>
:::success
**When debugging tests**, it is a very good idea to *read the test implementation* in the `tests` directory. The test files are extensively commented to tell you what each assertion is checking, which will be very helpful in debugging!
For more debugging help, see the [**Debugging**](#Debugging) section!
:::
## Testing with sanitizers
Even if you have passed the correctness tests for a section, make sure that your code does not contain possible race conditions! You can check this by recompiling with the `TSAN` flag enabled and then re-running your tests:
```shell
build$ make clean all TSAN=1 -j # -j enables parallel computing!
```
For more info on testing your work with sanitizers, and how to read the TSAN output, see [this section](https://csci0300.github.io/assign/projects/project5.html#Thread-Sanitizers) (from the Project 5A handout).
# Debugging
:::danger
While debugging this assignment, it will be **incredibly helpful** to compile and run the tests individually--they have a lot of output that `make check` suppresses! Since each test is just its own C++ file, we can compile and execute them like any other file. So, for example, to run `test_join` individually, do:
```shell
build$ make test_join
./test_join
```
:::
All the debugging techniques you've learned throughout the course apply to this project too. Finding bugs in distributed systems can be challenging, but we are sure you can do it! 👍
## Troubleshooting failure messages
Here are some common error outputs from the test suite, and hints for how do deal with them.
* `Assert failed in function {function} on line {line}`
* This type of error means that your implementation runs without failure. However, your implementation's behavior does not match the expected output. GDB will be the most helpful tool for debugging this kind of failure.
* The executables that correspond to all tests can be found in the `build` directory and can be run in GDB with the command `gdb {test_name}`.
* The best place to start is to set a breakpoint at the test function you're failing (for example `test_query`) and then step through this function to see where your implementation's behavior differs from what is expected.
* `./test.sh: line 69: Segmentation fault (core dumped) "$EXEC" > "$TMP_STDOUT" 2> "$TMP_STDERR"`
* This indicates that a segfault occured during the execution of the test, so you likely access invalid memory somewhere.
* GDB is again going to help you debug this. You can run the failing test in GDB with the command `gdb {test_name}` from the `build` directory to run a specific test in GDB.
* For a segfault, the best place to start is to just let the program run in GDB without any breakpoints. Once the segfault is reached, do a backtrace and look for the last frame in the trace that corresponds with code that you were responsible for writing. This function will be the best place to start looking in terms of tracking down the source of the fault!
## Hanging Tests
If a specific test remains running for more than about a minute, this is a sign that your implementation contains a deadlock. For this, GDB's multi-threaded debugging tools will be useful. Again, you can run the particular test in GDB with the command `gdb {test_name}` from the `build` directory.
After letting the program run in GDB for a bit, you can use `Ctrl-C` to pause the execution of all threads. After doing this, you can use the command `info threads` to see a list of all of the running threads and where they are in execution.
If it seems like a lot of threads are waiting on a mutex (their function is listed as `_lock_wait`), you can select one of these threads (with the command `thread <t_id>`), and look at its backtrace. If you look at the frame just before the frame for the `lock()` function, you should be able to see which of your mutexes it is waiting for. You can get information about this mutex with the command `p <mutex>`. Some of the more useful information that this shows you is the ID of the thread that currently holds the mutex!
# Extra Credit
**For this project, graduate students taking CSCI 1310 do not need to complete extra credit work for this assignment.**
## Implementing a Dynamic Shardcontroller
You have a fully functional distributed system capable of reconfiguration to move shards between servers now. But it still implements the simple scheme that partitions the key space equally between your servers.
In the real world, keys (and therefore shards) are not equally popular. For example, celebrities on X or Instagram have many more followers than most other users. If a shard stores a celebrity's timeline, it will receive many more requests than others, which could overload that shard!
**Think about how you could adapt your shardcontroller to implement a smarter redistribution scheme that takes into account how busy the shards are.**
Then, design and implement a scheme for a dynamic shardcontroller that reacts to load. Your design will likely involve adding new state and messages to the shardcontroller and servers. You'll need to provide proof of your improvements (for example, subjecting your new system and your old one to similar loads and collecting statistics on how frequently each server is contacted) to show how you've improved system throughput.
There is no single right answer here; we will award credit for any reasonable scheme.
# Handing In & Grading
### Handin instructions
To submit your work, you should do the following:
1. Be sure to push your code and test it on the grading server. In particular, be sure to click the :sparkles: **Check with sanitizers** :sparkles: button to run the tests with the thread sanitizer enabled. If you encounter issues, remember that you can run the thread sanitizer locally by compiling with `make -j TSAN=1` (more info [here](#Testing-with-sanitizers)).
2. **Fill out the readme file `README-5B.md`**, located in your repo's `kvstore directory.
<details><summary><span><b>Remind me again what the README should contain?</b></span></summary>
Your `README-5B.md` file will include the following:
* Any design decisions you made and comments for graders, under “Design Overview”. If there’s nothing interesting to say, just list “None”.
* Any collaborators and citations for help that you received, under "Collaborators". CS 300 encourages collaboration, but we expect you to acknowledge help you received, as is standard academic practice.
* Your answers to the questions regarding your `GDPRDelete()` implementation.
</details>
### Grading breakdown
This project is graded out of 100 points:
* **42% (42 points)** for passing the B1 tests (6 points per test).
* **30% (30 points)** for passing the B2 tests (10 points per test).
* **28% (28 points)** for passing the B3 tests (14 points per test).
**Congrats!** You're officially done with the last project for the class :clap:
---
<small>_Acknowledgements:_ This project was developed for CS 300. The current iteration was developed by Carolyn Zech, Richard Tang, Nicholas DeMarinis, and Malte Schwarzkopf.</small>